

Why AI + MCP is a massive tailwind for software incumbents, compute and storage
Looking at Cursor as an example

I bet most readers have encountered the following frustration with any type of Deep Research or even basic LLM query. You ask your LLM to pull data from a specific source (in my case, it was CEFConnect.com). You look at the “Thinking” output of Gemini or ChatGPT or your LLM of choice and see it can’t pull the data you want because of cookies or credentials or reCAPTCHA or something else. Something like below pops up:
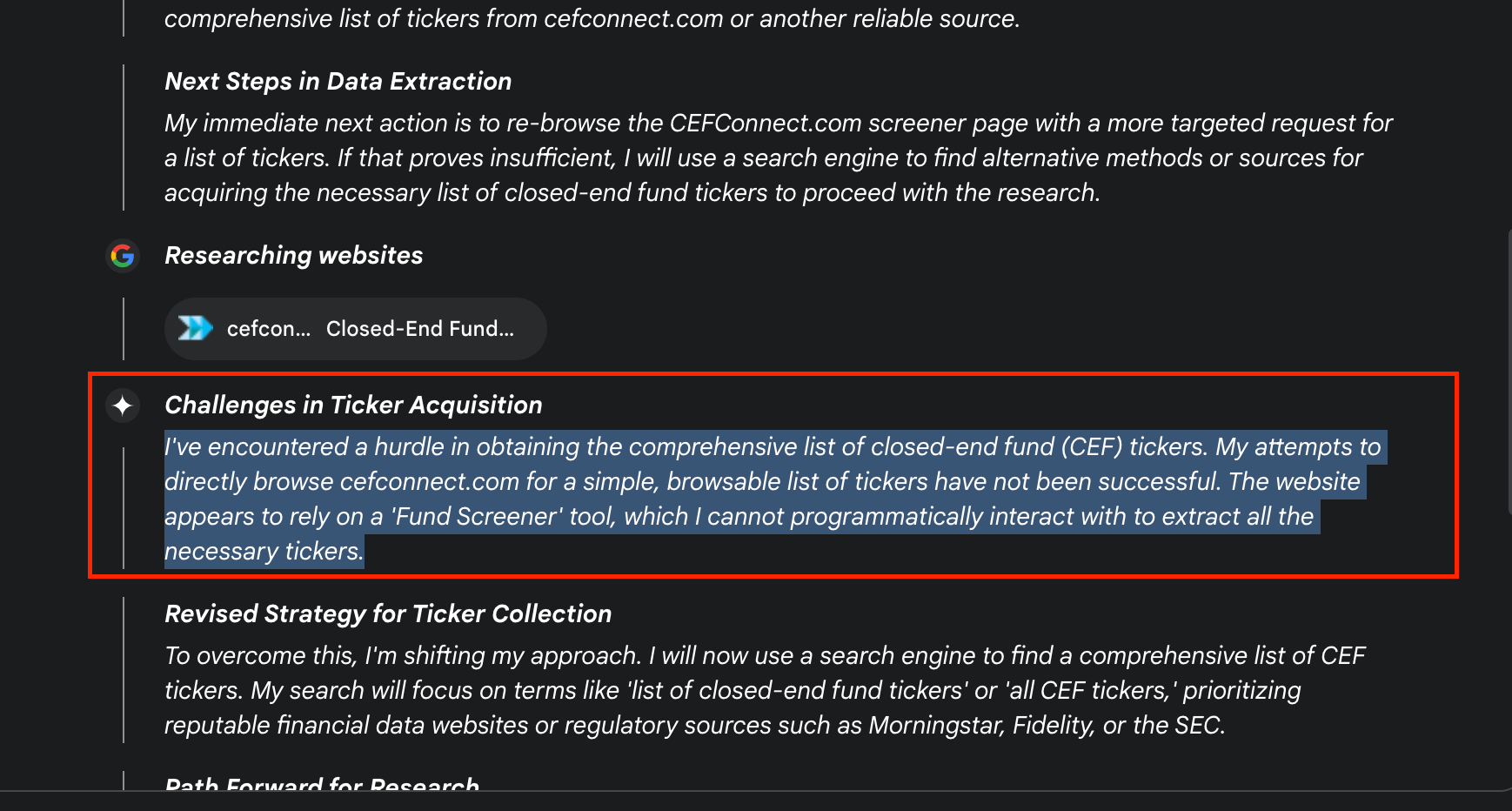

The AI can’t do what you wanted because:
the website…I cannot programmatically interact with…
the browsing tool was unable to parse the table…
Next, the LLM goes on a wild goose chase of pulling anything on the internet that resembles your source. 45 minutes later, you end up with a hodge-podge of AI slop that wasn’t what you asked for.
A couple weeks ago, I assumed this problem would be solved by a host of companies that have written software to correctly pull from websites like sec.gov through APIs and/or have access to protected data via licensing deals. Fintool is a good example of one such company. While I still believe these companies will play a key role in the AI ecosystem, I am now convinced Model Context Protocol - or MCP - will 1) make the big LLMs better at solving the hard-to-access-data problem and 2) lead to an explosion in demand in incumbent software providers, compute and storage.
The easiest way I know of to explain MCP is it’s the AI equivalent of giving other websites access to Google services or some other company’s data. Every time you go through something like:

You are giving other websites a token they can use to access your data from another company, like Google. MCP is the AI handshake equivalent here.
I learn best by example and did not fully understand MCP until I used it via Cursor, the most popular AI coding editor. Here’s how the aforementioned problem pops up in coding: many companies now use a service called Sentry to figure out when users are running into bugs. Sentry alerts you when an exception pops up in your code like below:

Before I knew Cursor could connect with Sentry over MCP, I used to paste information from Sentry into Cursor, assuming Sentry was credentials-protected and Cursor could not access it. Turns out Cursor can access Sentry and all types of other data through what I see as an “AI app store”:


Integration of these tools is generally one click and then signing into an app or pasting a one-time code. It took me <15m to set up for Sentry, GitHub and Linear (JIRA / Atlassian tool like tracking system):

Now, in Cursor I can do the following:

Cursor also recently announced an integration with Slack that gives it access to Slack threads and other data and can translate talk to action:
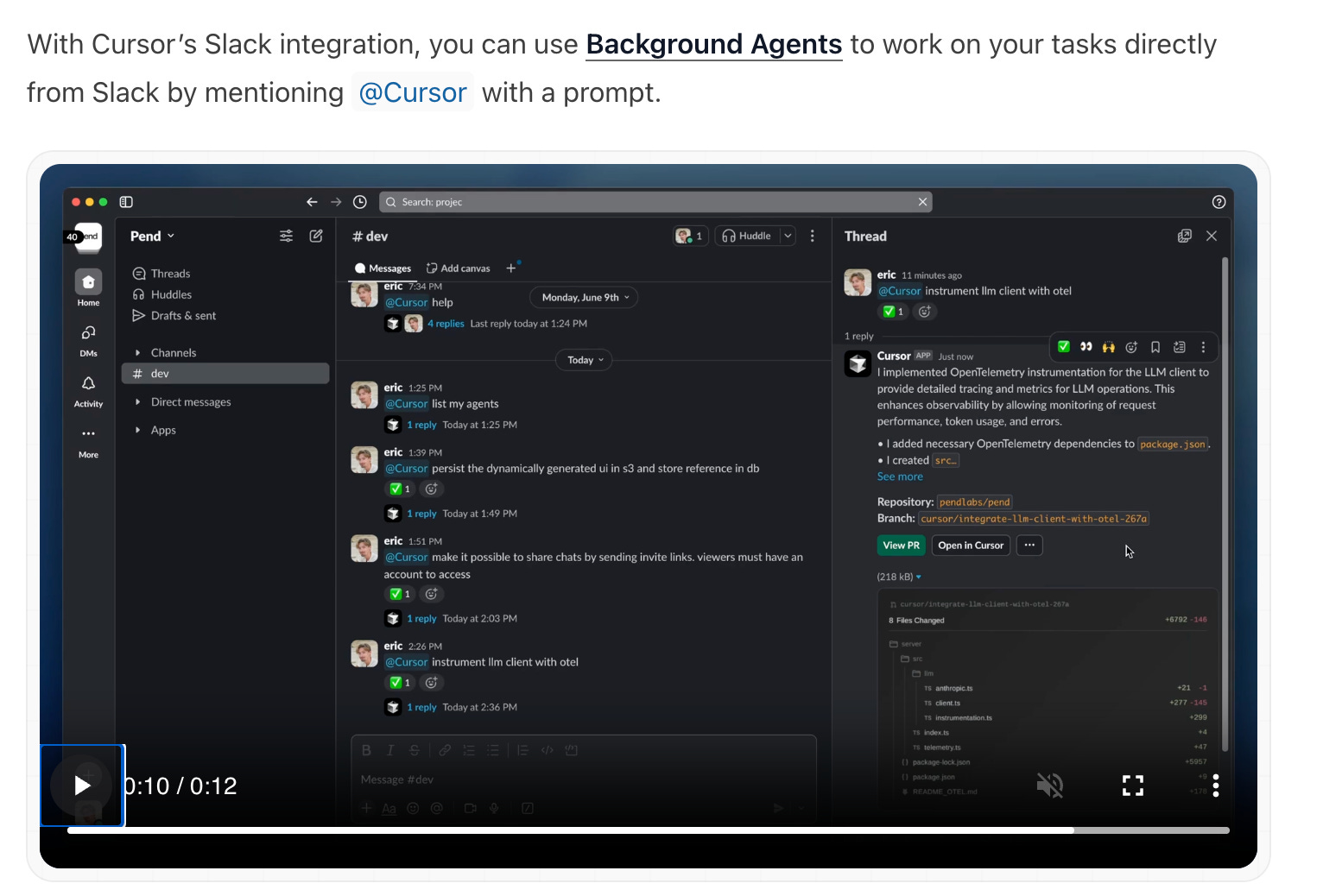
We now have robot employees who can see our Slack conversations, read them, complete work and report back. I think Zoom / Gong / any meeting recording tool is a natural MCP candidate where AI tools can just listen in and anticipate your company’s needs without being told exactly what to do. Additionally, the combination of many integrated MCP servers to a client like Cursor makes Cursor way more helpful, as Cursor can now say:
“Hey, I looked at GitHub, cross-referenced your code and Sentry, checked out some recent JIRA tickets, and I think you’re forgetting about another code and upcoming change that will cause merge conflicts. So I sent a Slack message to the developers who are working on it and changed your code so it can merge cleanly. I also posted on the relevant JIRA tickets with my plan for a staged release to mitigate any potential issues.”
MCP makes this all possible by allowing application developers to share their data with LLMs in a format LLMs can parse - no more “the browsing tool was unable to parse this table” or “I can’t access this website without credentials”. Credit Anthropic for inventing MCP and providing this great explanation in their PR release from November 24’.
…even the most sophisticated models are constrained by their isolation from data—trapped behind information silos and legacy systems. Every new data source requires its own custom implementation, making truly connected systems difficult to scale.
MCP addresses this challenge. It provides a universal, open standard for connecting AI systems with data sources, replacing fragmented integrations with a single protocol. The result is a simpler, more reliable way to give AI systems access to the data they need.
Instead of maintaining separate connectors for each data source, developers can now build against a standard protocol. As the ecosystem matures, AI systems will maintain context as they move between different tools and datasets, replacing today's fragmented integrations with a more sustainable architecture.
Who knows if MCP will stick around like HTTP as the go-to protocol for allowing apps to communicate, but it’s a start and is clearly working. In the example I started with, I could build a CEFConnect.com MCP server that hands over tickers, Z scores, NAV discounts and more to Anthropic. Then, whatever MCP-compliant LLM I used (the MCP client) would be able to access the MCP server and answer all my closed-end fund questions.
Why does this matter from an investing perspective?
My view is MCP makes software incumbents like Atlassian, Salesforce and Microsoft (via GitHub) stickier and arguably could reduce churn and increase customer LTV over time. Not all MCP servers are going to work the same, and it’s now likely harder to migrate software systems if you have AI workflows that depend on specific MCP server responses.
Additionally, MCP increases the storage and compute needs of AI systems. Look at the below:

Cursor is already telling me the amount of tools I have enabled (91 tools across 3 integrations) is degrading performance. I am confident Cursor is working right now to allow you to add way more tools without degrading performance; what this probably means in practice is higher cloud provider bills.
MCP now gives AI way, way more context. So context windows have to be larger; queries have more input tokens; outputs are longer. Going from context to response requires more compute because 1) MCP clients now have to query one or more MCP servers to get context & hold context in memory and 2) context is larger so the LLM has to look at more data. IMO this is going to be a significant tailwind for Azure, GCP and AWS.
At the storage level, more queries are going to happen because MCP makes way more interesting queries possible. Instead of “How do I fix this issue?, you can now ask “How do I fix this issue and are there any related issues from JIRA I could fix in the process?”. What this means is more inputs and outputs have to be stored. If you imagine a future 5 years out where there are millions of MCP servers and clients and LLMs can re-query with limited constraints, we are looking at an exponential growth rate in AI data & compute. I say exponential and not linear because a network of AI clients and servers is now growing, all of which can communicate back and forth.
At the storage level, I remain long Backblaze and wanted to call out this Fortune article that while not directly on MCP has some good stats on the growth BLZE is seeing in AI-related customers & data:
While some customers may opt to both store their data and utilize the compute power and resources of a large cloud provider such as Amazon Web Services, Budman said increasingly customers are separating storage and compute between different companies. This trend has given cloud storage companies such as Backblaze a boost.
AI use cases were Backblaze’s number one driver of growth in the first quarter, said Budman. Its AI customer count shot up 66% year-over-year as of the first quarter, and the data stored by those companies with Backblaze grew by 25 times over the same period, he said.
MCP to me is pouring kerosene on the fire that is the growth of compute and storage. AI through MCP is getting a lot more useful for customers, and more useful means a lot more usage.